
本文将从技术原理、核心优势、应用场景及落地实践等方面,对该技术进行系统性解析。
一、先进工艺节点的检测挑战与技术缺口
当前半导体制造技术正经历关键变革:鳍式场效应晶体管逐步被全环绕栅极(GAA)纳米带晶体管替代,中段制程(MOL)因多重图形化技术的应用,堆叠复杂度持续增加。这一变革导致致命缺陷多隐匿于 3D 结构内部,传统光学检测手段难以有效识别。
同时,先进工艺节点的缺陷呈现显著的产品特异性,集中分布于特定工艺 - 版图组合的 “热点区域”,此类缺陷由芯片设计固有的版图特征引发,成为影响良率的核心因素。
行业面临的核心矛盾在于:电子束电压衬度检测是识别电学缺陷的关键技术,但传统电子束检测采用光栅扫描模式,效率远低于光学检测,无法匹配大批量生产的需求。DirectScan 技术的出现,为破解这一矛盾提供了可行路径。

二、DirectScan 核心技术架构:PointScan 的创新逻辑
DirectScan 检测方案由eProbe 电子束检测工具、FIRE GDS 版图分析平台及Exensio 大数据智能分析平台三大核心组件构成,其技术突破的核心在于PointScan 扫描技术对传统电子束检测逻辑的重构,主要体现在以下三方面:
1
设计感知驱动的靶向检测
传统电子束检测采用无差别光栅扫描,需覆盖包括介质区域在内的全部区域,且无法识别被测目标的图形特征;PointScan 技术具备非接触式电学测试特性,可精准跳转至目标器件的关键位置(如焊盘、接触点),仅对有效检测区域实施电压衬度检测,完全规避介质区域的无效扫描,实现 “按需检测”。

2
检测效率的量级提升
通过 FIRE 平台的精细化版图分析,可精准筛选出需检测的 “关键区域”,大幅缩减检测范围:
后段制程金属 3 层通孔检测:仅需扫描总可检测面积的 2.5%
中段制程栅极 - 漏极短路检测:仅需扫描总接触点的 1%
栅极残筋检测:可规避 50%-75% 的介质区域,检测面积缩减至传统方案的 10% 以下
基于上述优化,PointScan 技术的检测吞吐量可达传统单束电子束检测设备的 20-100 倍,每小时可完成数十亿个被测器件的扫描。
3
设计感知学习与属性分析能力
DirectScan 与 FIRE 平台的深度整合,可实现跨多层版图的属性提取,包括触点类型(漏极 / 栅极)、晶体管阈值电压、极性、与扩散区隔离槽的距离等关键参数。
eProbe 输出的 KLARF格式数据含专属属性识别码,可与版图特征精准匹配,工程师可直接计算特定属性或属性组合对应的缺陷率,快速定位高风险晶体管类型与版图设计方案,为工艺优化提供数据支撑。
三、高难度场景的应用突破
PointScan 技术的低电荷沉积特性,使其在传统电子束检测难以覆盖的场景中实现突破:
背侧供电网络(BSPDN)晶圆检测
键合晶圆形成的绝缘层会阻碍电荷传导,导致传统电子束检测出现电荷累积、电子束偏折与失焦问题;PointScan 技术大幅降低单位面积电荷沉积量,有效缓解上述问题,已完成实际应用验证。
3D DRAM检测
3D DRAM 的结构特性同样易引发电荷累积,此前检测难度较高,DirectScan 技术的应用使该类器件的精准检测成为可能。
DRAM 阵列短路检测
独有的可控 “充电 - 检测” 功能,可在指定位置施加电荷后跳转至目标区域采集电压衬度信号,使特定岛状节点呈现高亮状态,清晰识别与浮空相邻触点的短路问题,该功能为传统光栅扫描技术所不具备。
四、行业落地实践与全流程应用
自 2022 年初起,eProbe 检测系统已在多家先进逻辑芯片制造工厂落地,目前两套设备投入大批量生产,第三套设备处于产能爬坡阶段,应用场景覆盖半导体制造全流程:
先进逻辑芯片制造
中段制程:GAA 栅极 - 漏极短路、栅极接触孔开路、栅极外延层 / 硅化物层开路检测
后段制程:M0 层、1X 层、2X 层系统性接触孔开路与金属布线短路检测
背侧供电网络:电源通孔、源极 / 漏极通孔接触孔开路与短路检测
随机逻辑电路漏电情况评估
先进 DRAM 制造(2024-2025 年)
外围电路:栅极 - 栅极残筋短路、栅极 - 漏极短路、字线 - 字线短路与开路检测及缺陷定位
存储阵列:基于可控 “充电 - 检测” 技术的存储节点短路检测
技术总结
在半导体制程向更精密 3D 架构演进的背景下,检测技术的创新成为保障良率的关键。DirectScan 方案通过 PointScan 靶向扫描技术、设计感知分析能力与产品特异性缺陷学习功能的融合,在保留电子束检测高灵敏度的基础上,实现了检测吞吐量的量级提升,同时破解了高难度场景的检测难题。
该技术不仅解决了先进工艺节点下缺陷“难识别、难检测” 的问题,更推动半导体检测从 “缺陷识别” 向 “工艺优化赋能” 升级,为下一代半导体制造提供了核心技术支撑和全新路径。
">DirectScan 技术解析:下一代半导体电子束检测的创新路径与应用赴一场中原古都之约!
登仙境老君山
徒步震撼挂壁公路
探秘龙门石窟千年石刻
赏洛阳牡丹倾城绽放
游少林寺、清明上河园、开封府
沉浸式感受大宋风华
全程双飞出行、四钻住宿、纯玩无购物
一次走遍河南
最经典、最震撼、最值得去的
山水与人文胜景
不负春日好时光

团期:4月14日
读者价:
(60周岁以下):5580元/人
(60周岁以上):5080元/人
报名方式:梅州日报社
1、咨询电话:13549160071 13823804287
2、现场报名:梅江区沿江路梅州日报社一楼广告部
参考航班时间

行程特色
★纯玩美景:奇境老君山+挂壁公路+郭亮村+嵩山少林寺+龙门石窟+牡丹花会+丽景门古街+开封府包公祠+清明上河园+万岁山武侠城
★特别安排:夜游《帝都洛阳》亮灯后的城门古意十足,登上城楼可看万家灯火
★舒适睡眠:全程入住网评四钻舒适型酒店
★精心策划:全程纯玩0购物,20人定制精品小包团
★独立成团:满18人派报社工作人员陪同,让您的旅行安心、省心尽情游玩
★特色美食:开封栾川山水豆腐、洛阳水席菜、灌汤小笼包、鲤鱼焙面、炒凉粉等开封小吃菜
行程速览
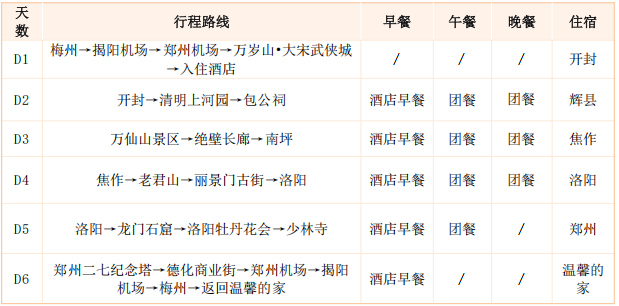
第一天
交通:梅州→揭阳机场→郑州机场→万岁山•大宋武侠城→入住酒店
住宿:开封网评4钻酒店
梅州指定地点统一集合出发,乘专车前往揭阳潮汕机场,乘飞机南方航空CZ6574(11:20-13:50)航班飞往【河南郑州】。


抵达后赴开封参观【万岁山•大宋武侠城】,这是一座以宋文化、城墙文化和七朝文化为景观核心、以大宋武侠文化为旅游特色、以森林自然为格调、兼具休闲功能的多主题、多景观的大型实景演出。踏入万岁山武侠城,仿佛一脚迈入北宋的繁华盛景。每一处细节都诉说着千年的故事。街边酒旗迎风招展,石板路蜿蜒延伸,仿佛时光在此静止,只留下满目的古风雅韵。

晚餐在景区自由品尝特色小吃,游玩结束后入住酒店休息。
第二天
交通:开封→清明上河园→包公祠
餐饮:酒店早餐︱团队餐︱团队餐
住宿:辉县网评四钻酒店

早餐后游览北宋大型民俗主题公园5A级旅游景区【清明上河园】。根据北宋画家张择端的国宝级北宋民俗画《清明上河图》以1:1的比例建造而成,观包拯迎宾、杨志卖刀、汴河大战、王员外招婿、水傀儡、女子马球、斗鸡、大宋科举、梁山好汉劫囚车、包拯巡河、气功喷火、民间咋杀等一系列北宋民俗表演,体验“一朝步入画卷、一日梦回千年”。

赠送欣赏:《沉浸式大宋奇幻游》,特别安排宋文化特色实景演出:《大宋民俗绝活》《王员外招婿》《岳飞枪挑小梁王》在这幅“百米长卷”上,它已被赋予了生命;白天,城里是徒步行走的人流,骑着骆驼的商队,小桥下潺潺的流水,吆着号子声的水手;夜晚,夜市上是忙碌的小商小贩,屋里准备歇息的夫妻,小酒馆里传出的猜拳声。
午餐品尝开封当地名小吃:灌汤小笼包子等。


参观【包公祠】。这里为纪念铁面无私包大人而修建的,威名驰誉天下,包龙图扶正祛邪、刚直不阿、美名传于古今!品味大宋文化,拜包龙图,领略人间正气!
结束后乘车付辉县(车程2小时)入住酒店休息。
第三天
交通:万仙山景区→绝壁长廊→南坪
餐饮:酒店早餐 ︱团队餐︱团队餐
住宿:焦作网评四钻酒店


餐后乘车约2个小时到达【万仙山景区】,走进万仙山,住农舍,食农家饭,闻炊烟袅袅,瞧百年老宅,看蓝天白云,听瀑鸟合鸣,走林间小道,吸太行氧吧,归返原始的韵味。

沿途游览【绝壁长廊】(1250米)郭亮洞、红岩绝壁大峡谷,欣赏风景如画的天池、参观奇特的崖上人家红石桥;体会大自然风光。参观【郭亮村】石头世界。
中餐后游览清幽山乡【南坪】观赏奇石日月星石、将军峰、黑龙潭、白龙潭、丹分沟。
结束后车赴焦作,晚餐后入住酒店休息。
特别安排:徒步穿越高悬石崖的绝壁长廊,走进原汁原味的石头村落。
第四天
交通:焦作→老君山→丽景门古街→洛阳
餐饮:酒店早餐 ︱团队餐︱团队餐
住宿:洛阳网评四钻酒店


早餐后乘车前往参观国家5A级旅游景区、世界地质公园【老君山】(参观时间约4-6小时),抵达后乘坐中灵索道开始登山。 抵达中天门之后登518级生财道或自费乘坐峰林索道,之后参观老君庙、南天门、玉皇顶、悬崖 栈道、北国石林、主峰马鬃岭、高空玻璃观景台、舍身崖、十里画屏,老君山金鼎等。观十里画屏之云海奇峰,赏老君金顶之无双圣境。


中餐后乘车赴洛阳,参观【丽景门古街】(游览时间1小时左右)走进明清古街,明媚的阳光洒在绿瓦红墙之间,那突兀横出的飞檐,那高高飘荡的商铺招牌旗号,那川流不息的行人,那一张张淡泊惬意的笑容,无一不反衬出老洛阳人的得意其乐。

特别安排:夜游《帝都洛阳》。夜幕降临,你将漫步在帝都洛阳,观赏盛唐武则天时期的天堂(外观)、明堂(外观),以及灯火璀璨的应天门(外观)夜景。
晚餐特别安排:品尝洛阳特色水席菜。
第五天
交通:洛阳→龙门石窟→洛阳牡丹花会→少林寺
餐饮:酒店早餐︱团餐︱无
住宿:郑州酒店


早餐后,乘车游览世界文化遗产、中国石刻艺术宝库【龙门石窟】(参观约2小时),龙门石窟与“敦煌莫高窟、大同云冈石窟、天水麦积山石窟”共称为中国四大石窟!龙门石窟开凿起于北魏孝文帝年间,连续大规模营造长达400余年,南北长达1公里,今存有窟龛2345个,造像10万余尊,碑刻题记2800余品。其中的卢舍那大佛,高17.14米,堪称龙门石窟造像艺术之典范的——奉先寺。


游览【洛阳牡丹园】(3月室内牡丹、4月室外牡丹为主)在千年古都洛阳,每年春暖花开之际,这座城市的大街小巷都被五彩斑斓的牡丹花所点缀,成为了一幅充满诗意的画卷。


乘车游览“千年古刹”中华武术发源地【少林寺】(游览约120分钟),观赏由少林弟子担纲,专为贵宾量身定做的精彩的【少林武术表演】(约30分钟),参观历经1400多年、现存240余座塔墓的佛教圣地【塔林】(约30分钟);
期间观赏:名扬中外的《少林小子功夫表演》。
结束后返回郑州,入住酒店休息。
第六天
交通:郑州机场→揭阳机场→梅州→返回温馨的家
餐饮:酒店早餐
住宿:温馨的家
酒店早餐后,乘车前往郑州机场乘飞机南方航空 CZ6573 08:30 时郑州起飞-10:00时抵达揭阳机场,乘专车返回梅州,结束愉快的河南之旅,返回温馨的家!
编辑:邓梓钰(实习) 叶晓洋
校对:张颖
">春赴中原!览太行奇景、赏国色牡丹......读者团河南双飞6日精华之旅等你报名!本质上,AI 重新定义了“优秀”基础设施的标准。相应地,平台设计的重心也从注重单一的芯片或服务器,转向了打造机架级、可扩展的系统,在功耗和预算有限的前提下,实现高效扩展。而这一转变背后的原因在于,推理与智能体 AI 工作负载持续增长且不间断运行,对高密度、全天候在线的算力需求正快速提升。
Futurum 在《Arm处于 AI 和数据中心变革的中心》报告中,把这一转变称为迈向“系统级协同”。设计的关键不再是堆多少算力,而是平台能不能有效地把加速器、CPU、内存、网络和软件协同起来。
正因如此,业界正加速迈向定制化机架级系统设计:即围绕 AI 负载特性、功耗波动和持续利用率来进行端到端设计的平台。越来越多的架构师开始重新思考计算底层设计,选择基于 Arm 架构来解决现代 AI 平台面临的多重约束。
AI 促使行业重构:转向定制化机架级系统
这一转变的核心原因,并非通用型标准化基础设施无法承载 AI,而是碎片化的系统设计,在 AI 规模化部署时,终将转化为真实可感的成本代价。
AI 工作负载在计算、内存、网络、存储及软件各环节紧密耦合。CPU 拖后腿,昂贵的加速器就会空等;功耗和散热波动,利用率就会下滑;数据管道、调度、编排未能针对平台调优,吞吐量就不可预测。峰值性能依然重要,但稳定性、每瓦性能和系统整体平衡性更关键。
Futurum 指出,超大规模云服务提供商正进行结构性调整,旨在实现算力的指数级增长,同时避免能耗的同步激增。Futurum 引用 Arm 的数据指出,到 2025 年末,出货到头部超大规模云服务提供商的算力中,有近 50% 是基于 Arm 架构。
架构师现在不再只看纸面跑分,而是更关心 AI 平台在实际应用中能否长期可靠地运行智能体 AI 和连续推理工作负载,比如:
长时间高负载下,系统表现如何?
在实际环境中,功耗限制和散热条件如何影响性能曲线?
在机架级系统中,计算层如何确保加速器能持续获得稳定的数据供给,而非仅停留在纸面参数上?
当能效、可扩展性与系统平衡性成为首要原则时,重新审视 CPU 底层架构就成了必然。也正因为此,Arm 凭借领先的架构和完善的生态,正是这场行业变革的核心所在。
在数据中心领域,Arm Neoverse 平台是推动这一转型的核心引擎。亚马逊云科技、Google、微软、NVIDIA 等头部超大规模云服务提供商与 AI 领军企业,都在基于 Arm 架构或采用 Arm 计算平台进行产品研发。Arm 的模式既能支持定制化系统设计,又能保持跨平台、跨生态、跨软件的一致性。对于想要构建高集成度平台、又不愿被单一技术路径绑定的团队而言,这种灵活性至关重要。
智能体 AI 与持续推理,
重塑规模化算力的经济逻辑
随着 AI 与通用计算工作负载的融合,AI 工作负载正在发生变化,基础设施也需随之调整,以支持多样化的工作负载特性。
行业重心正在转向智能体 AI,而智能体 AI 本质上就是一个连续推理系统。智能体并不是简单地给出一个答案, 而是会规划、调用工具、检索数据、验证结果,如此循环往复。由此便形成了连续推理模式:稳定不间断的词元 (token) 生成任务,请求类型趋于多元化,围绕加速器的编排和数据迁移任务变得更繁重。
在智能体 AI 里,CPU 不再是配角, 而是整个 AI 系统的控制中枢。CPU 负责协调控制、调度任务、管理 IO、处理网络与存储服务、执行安全策略,并在模型、上下文及工具链不断演进的过程中,维持整个系统的平衡。
以承载大语言模型 (LLM) 的服务为例,它可能同时处理成百上千的并发请求。就算加速器负责核心计算,CPU 也要承担请求权限控制、分词和预处理、批处理和队列调度、数据迁移编排,以及针对模型权重与 KV 缓存的数据路径协调等。到了智能体工作流,CPU 的工作负担进一步扩展,还要承担工具调用、检索流程、结构化输出验证、多步调度等持续运行的任务。
这一切都表明,CPU的重要性远超许多团队的预期。如果 CPU 跟不上编排节奏,数据迁移、处理流程和加速器都会被“卡住”,面临结构性的闲置风险。
融合型 AI 数据中心的建设,彰显了 Arm 架构的强劲势头
Arm 的发展势头正在加快。在业内领先的集成式 AI 系统中,基于 Neoverse 平台的 CPU 被广泛用于智能体推理密集型系统的编排层,尤其适合追求高能效、可预测扩展能力和大规模部署的应用场景。
独立测试也印证了现代 CPU 基础平台在“AI 相关”工作负载中的价值。Futurum 旗下 Signal65 的独立基准测试对比了基于 Arm Neoverse 平台的 Amazon Graviton4 与同级的 AMD和 IntelEC2 实例,结果显示:在生成式 AI (Llama-3.1-8B)、数据库 (Redis)、机器学习(XGBoost)、网络 (Nginx) 等测试的各种工作负载中,基于 Neoverse 平台的 Graviton4 在性能和性价比方面大幅领先。
测试结果直接反映了智能体 AI 数据中心的现状:LLM、检索层、缓存、Web/API、传统机器学习等全都处于智能体系统的关键路径上,只有当 CPU 兼具速度与能效时,整体才能更好地扩展。
最新的机架级 AI 系统在架构设计上,均采用定制化加速器层以及基于 Arm 架构的 CPU 层的组合,由后者承担调度编排、数据迁移与智能体推理预处理等关键任务。NVIDIA Grace Hopper、Grace Blackwell 等系列产品,将 NVIDIA GPU与基于 Neoverse 架构的 Grace CPU 深度融合。而其最新机架级平台 Vera Rubin NVL72,更是在系统内集成 72 颗 Rubin GPU 与 36 颗基于 Arm 架构的 Vera CPU,专为交互式、深度推理型智能体 AI 优化,显著降低推理成本。
亚马逊云科技也在走同样的系统级路线:Amazon Trainium3 UltraServer 把 Trainium3 加速器芯片与 Graviton CPU 结合,强化了“融合型”设计理念:将加速器与定制的高性能、高能效 CPU 相匹配,以实现高效扩展。
“提供更优选择”不再是偏好,而是硬性要求
AI 系统迭代太快,固定架构已无法适配其发展节奏,因此为客户提供更优选择已成为风险管理的必要举措。
系统架构师想要的是:
平台能适应不同代的硬件、多样的工作负载配置及各异的部署环境;
软件可移植,以降低系统变更成本。
与此同时,系统架构师希望避免因过度依赖单一厂商,而导致在模型组合变化、业务规模扩张或新需求出现时陷入被动。在智能体时代尤其如此:推理形态不断变化,上下文更长、工具调用更多、多模态输入更频繁、全天候工作负载更普遍,效率和平衡远比峰值跑分重要。
Arm 架构在提升系统性能的同时,保持跨平台一致性。Arm 架构不仅引入了现代 AI 基础设施所需的关键特性,而且拥有强大的软件生态支持。Arm 计算子系统 (CSS) 提供经过验证的基础设施级模块,既加速了芯片开发,又保留了合作伙伴间的差异化与选择权。对于所有基于 Arm 架构的平台,一致性贯穿始终,云工作负载迁移至 Arm 平台也极为便捷。同时,在软件层面,Arm 生态助力团队在不同环境与平台间拥有一致连贯的基础,从而加速开发进程,无需重写所有代码。
智能体 AI 经济重塑 CPU 选择格局,Arm Neoverse 平台成头部厂商首选
系统架构师之所以倾向于 Arm 平台,因为它精准匹配定制AI 系统的核心需求:能效、可扩展性及每瓦性能。能效重要,因为功耗和预算是硬上限;系统平衡和 CPU 性能重要,因为加速器闲置成本极高;一致性重要,因为 AI 基础设施变化快、跨环境部署日益增多。
在融合型智能体 AI 数据中心里,面对持续推理的应用需求,上述优先事项变成了上线即需满足的硬性指标。智能体系统不只需要能生成词元的加速器,更需要以 CPU 为核心的编排能力,在网络、存储、调度、安全层面,持续、高效、大规模地把资源利用起来。
Arm 如今的强劲增长正源于此:Neoverse 正成为智能体时代的 CPU 基础平台,作为计算头节点,是让 AI 系统保持高效、一致并面向未来的核心控制中枢。
" alt="为何AI数据中心的系统架构师首选Arm平台">2025年3月19日





